

Vibe Coding’s Hidden Bill: Security, Maintainability, and the NIST Playbook
Vibe coding meets NIST SSDF: measure what matters, avoid unforseen costs, cut duplicate debt, and ship secure code every sprint.


Vibe coding is here. Adoption is high, tools feel fast, and leaders want the headline ROI. The problem is that perception isn’t delivery. Real teams report slowdowns on complex work, duplication creep, and a steady drip of security risk. I will show how to measure the truth, set hard guardrails, and use the NIST playbook to run vibe coding like a business, not a demo.
The speed story breaks under real load
Developers feel faster when a model fills the screen with code. Leaders love the screenshot. Reality is harsher. A rigorous 2025 randomized trial found that experienced open-source maintainers were approximately 19% slower with AI on real fixes and features. The cause was not a lack of code. It was prompt thrashing, reviewing, and reworking that eroded first-draft speed.
Short tasks get faster. Systems work does not. That is why the “55% faster” narrative we often read about collapses at scale. It measures a single task in a lab. It does not reflect how code moves from idea to merged, deployable, and stable. If you anchor your strategy on a marketing headline, you will buy speed and inherit churn.
Here is how I measure what matters:
Cycle time to merge across repos, by risk tier, and by AI involvement.
OWASP‑mapped findings per PR from SAST, SCA, and secret scans.
Security incidents linked to AI‑touched code with clear provenance.
Developer hours saved per story captured in your planning system.
Track these four for every AI‑touched PR. Break them out by service criticality. When cycle time blips while findings rise, your “speed” is a mirage. When hours saved increase and findings remain steady, you have real productivity.
Use vibe coding only when code quality and security scanners are clean, and developers are not overwhelmed with troubleshooting as a result. Otherwise, throttle usage. The goal is a balanced flow, not a surge of dopamine.
Maintainability is where the debt compounds
You don’t pay the duplication bill on day one. You pay it in sprint six when a patch hits one copy but misses three others. Large repo analyses show that cloned code has risen from roughly 8 percent to over 12 percent of changes since 2021. Refactoring activity is falling at the same time. That is a recipe for silent drag.
I plant two flags:
Fail PRs that add large duplicate blocks without a written justification.
Require a short rationale block or inline comments on any AI‑generated section.
Engineers hate bureaucracy. I do too. This is not bureaucracy. It is clarity. If you let paste‑and‑proceed slip through, your mean time to understand climbs. Your defect rate climbs. Your team's energy falls.
For juniors, I’d pair every AI‑touched PR with a senior reviewer. I allow AI‑generated tests, but I force a human to deduplicate and challenge them. Otherwise, the tests inherit the same assumptions as the code and give you a false clean bill.
If you want a simple mental model, treat the model like a capable junior. It writes quickly. It needs standards and feedback. It does not own architecture.
Security must gate the merge, not the press release
About one in three AI‑generated snippets contain vulnerabilities across dozens of CWE categories. The usual suspects apply. Injection. Weak randomness. XSS. Secrets where they never should be. You will not audit your way out after release. Put the gates where they belong.
My minimum bar to ship AI‑touched code:
Clean SAST, SCA, and secret scans plus a senior review on every PR.
Red team review when the change touches authentication, payments, or any safety‑critical path.
Filters on for public‑code matches with vendor indemnity, and legal review for any flagged snippet.
Internal provenance logs that record prompts and acceptance decisions for audit.
Map this to NIST SSDF so executives can track it like a program. It even has a specific AI extension (https://www.nist.gov/publications/secure-software-development-practices-generative-ai-and-dual-use-foundation-models-ssdf). Use PW.1 for policy, RV.1 and RV.8 for review and analysis, and CM.1 for integrity. Tie OWASP categories to your findings so the board sees familiar risk language. Most importantly, never let “AI wrote it” become a reason to lower a gate. Models replicate the patterns they see. That includes unsafe ones.
Cost isn’t in the license, it is the thrash
Learn from my mistakes. My own costs in developing the NIST CSF 2.0 MCP Server ( told the story before the metrics did. Claude Code Opus cost me five times as much as Sonnet for the same class of coding sessions. I spent most of my time troubleshooting. I have burned about $1,000 in Claude code credits to date. The majority went to prompting, reruns, and validation, not finished capability. I use the SuperClaude plugin and have extensively utilized the /sc:troubleshoot command to the point where I’m sick of it.
That isn’t a complaint. It is a warning and a learning experience. Token costs rise fast when you push big contexts and agentic runs. CI minutes rise when you chase failing tests. Engineering hours rise when suggestions drift from your architecture or APIs. Add troubleshooting, and you can wipe out the savings that initially seemed obvious.
So set a rule you can defend in a QBR. As I mentioned above, heavy usage is fine when scanners are clean and developers aren’t overwhelmed by rework. If either signal flips, ratchet down to the goldilocks zone. Use the smaller model by default and escalate when a proven need arises. Track spend per story and spend per merged PR the same way you track cloud cost per product feature.
If you want a deeper governance lens for cost, the CARE Framework is the right fit. Create a policy for model selection. Adapt usage by data class. Run with live controls and spend dashboards. Evolve with quarterly baselines and drift detection.
Vibe coding under NIST SSDF: the rules of the road
This is how I codify policy so teams can move fast without worrying about their PR being blocked:
Scope by risk tier. Low‑risk paths may auto‑merge when tests and scanners are clean. Regulated or safety‑critical paths never do.
Prompt hygiene. No proprietary code to public clouds unless it is through an approved enterprise tenant with logging. Prefer self‑hosted or private endpoints for sensitive work.
Tests are first‑class. Allow AI to draft tests. Require a human to review, deduplicate, and expand them.
Documentation is part of the diff. Inline comments or a rationale block for every AI‑generated section.
Duplication control. Fail PRs that repeat large blocks. Allow exceptions only behind a tracked refactor ticket.
Provenance and indemnity. Enable public‑code filters, rely on vendor indemnity for copyright, and keep internal logs for traceability.
This is about maintaining velocity without compromising quality. It respects SSDF, bridges to OWASP, and sets a floor the auditors can understand.
My NIST CSF 2.0 MCP Server: an easy button for assessment and answers
I built the NIST CSF 2.0 MCP Server to give security leaders an easy button. The goal is simple. Run a CSF 2.0 assessment fast. Query your data through a large language model without spelunking through spreadsheets. Get a clear picture of program health and drift. No ceremony.
This is an assessment server, not an enforcement engine. It does not block merges. It surfaces gaps and answers questions leaders actually ask.
The core architecture is a Multi‑Protocol Service Layer with Domain‑Driven Design. The domain logic for cybersecurity assessments sits in a clean core. Adapters expose the same capabilities to different clients and protocols. Today, that includes a GUI and Claude Desktop. ChatGPT support is next. The pattern keeps the domain testable and the clients flexible.
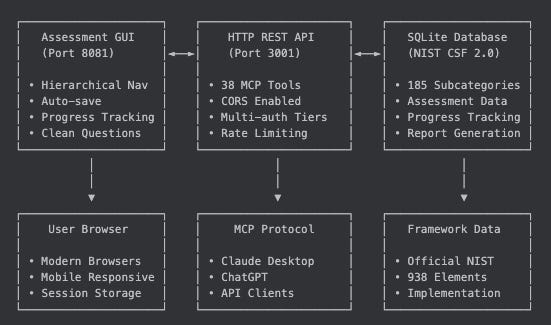
How it helps your program today:
Fast baseline and drift checks. Quarterly snapshots and side‑by‑side comparisons support the “Evolve” function of CSF 2.0.
Query once, answer anywhere. Executives ask plain language questions. The service layer retrieves and structures the answer.
Evidence capture. Assessments and queries live in one place, ready for audits and board updates.
Where I draw the bright lines
I will not weaken security gates for a demo.
I will not accept duplicate blocks without a rationale and a plan to refactor.
I will not let AI-generated code ship in authentication or financial paths without a red team pass.
I will not claim speed without proof in cycle time, findings, incidents, and hours.
You can move fast. You can be safe. You cannot pretend you have both if you do not measure.
What you can do this quarter
Publish a one‑page vibe coding policy mapped to NIST SSDF and CSF 2.0.
Turn on scanning everywhere. CodeQL or equivalent for SAST. SCA on every dependency. Secret scanning on all repos.
Label and track AI‑touched PRs. Create dashboards for cycle time, OWASP findings, incidents, and hours saved.
Pilot a heavy‑use sprint in a low‑risk service with a smaller model default. Compare results to your baseline.
Run a CSF 2.0 assessment with the MCP Server. Use it to set your CARE Evolve baseline and build your board story.
Two final notes. First, vibe coding isn’t a free lunch. Actually, it can be a really freaking expensive one.
Second, with guardrails and measurement, it can be a real advantage. Choose discipline over vibes.
Key Takeaway: Vibe coding pays only when you enforce SSDF-level gates, control duplication, and prove value with hard metrics that stand up in a boardroom.
Call to Action
👉 Clone the GitHub repo is located at https://github.com/rocklambros/nist-csf-2-mcp-server, start to play and contribute
👉 Book a Complimentary AI Risk Review HERE
👉 Subscribe for more AI security and governance insights with the occasional rant.
👉 Services and advisory: https://www.rockcyber.com
