

I Built TokenTally After a Friend Asked: “How Do I Budget for ChatGPT?”
A friend consulting a startup asked me: “This business wants a chatbot on their website. They’re using ChatGPT. How do I tell them what it’ll cost?” I didn’t have a good answer. So I vibe coded one.

The Hidden Tax Eating Your AI Budget
Most AI startups are burning cash without realizing it. Not on flashy offices or big salaries. On tokens.
AI startups today face a hidden cost crisis. Many early-stage companies are burning through cash because they misjudge the costs of AI model usage, especially token-based consumption. Unlike traditional software (where serving one more user costs almost nothing), large language models (LLMs) incur significant variable costs on every use[1]. As a result, AI startups often suffer from structurally thin margins due to costs rising in tandem with (or faster than) revenue, making profitability elusive. For example, Anthropic’s generative AI services reported gross margins of only ~50–55%, versus ~77% for typical cloud software, due largely to hefty inference costs.
Token costs dropped in the past year. You’d think that would solve the problem. It didn’t. Usage exploded even faster. Bigger context windows mean more tokens per request. Multi-turn conversations accumulate context. Agentic workflows chain multiple calls together. What looked like a $50 monthly bill six months ago is now $5,000. And you can’t explain why.
One AI coding startup I spoke with was burning through $500,000 in OpenAI credits annually. They got it down to $50,000 with better model selection and caching strategies. That $450,000 difference? That’s the gap between profitability and shutting down.
Why Your Spreadsheet Won’t Save You
You can’t budget AI costs the same way you budget server costs. Traditional cloud infrastructure scales linearly. Add a user, add a server, and costs go up predictably. AI doesn’t work that way.
Output tokens cost 4x to 8x more than input tokens. A Claude Sonnet 4 input token runs $3 per million tokens (MTOK). The output? $15 per MTOK. If your chatbot gives verbose answers, your costs quintuple. Nobody budgets for that.
Then there’s context accumulation. Every conversation turn adds to the context window.
Turn one: you’re processing 500 tokens.
Turn five: you’re processing 2,000 tokens.
Same user, same feature, 4x the cost. Your finance team sees the spike and assumes something broke. Nothing broke. That’s just how LLM conversations work.
Prompt caching saves you money, but only if you understand it. Claude offers 90% savings on cached system prompts. Your system prompt costs $3 per million tokens on first use. After caching? $0.30 per million. That’s real money at scale. A 10,000-conversation monthly load goes from $177 to $75. But you have to know it exists. You have to model for it.
Most cost calculators ignore all of this. They assume single-shot prompts. They treat every API call the same. They give you a number that’s wrong the moment a user asks a follow-up question.
Figure 1: Real LLM Costs for LLM Chatbot Conversations
Enter TokenTally: Built for Real Conversations
I built TokenTally because I was tired of guessing. My friend’s question about budgeting that startup’s chatbot wasn’t rhetorical. He needed an actual answer. So I sat down and wrote one.
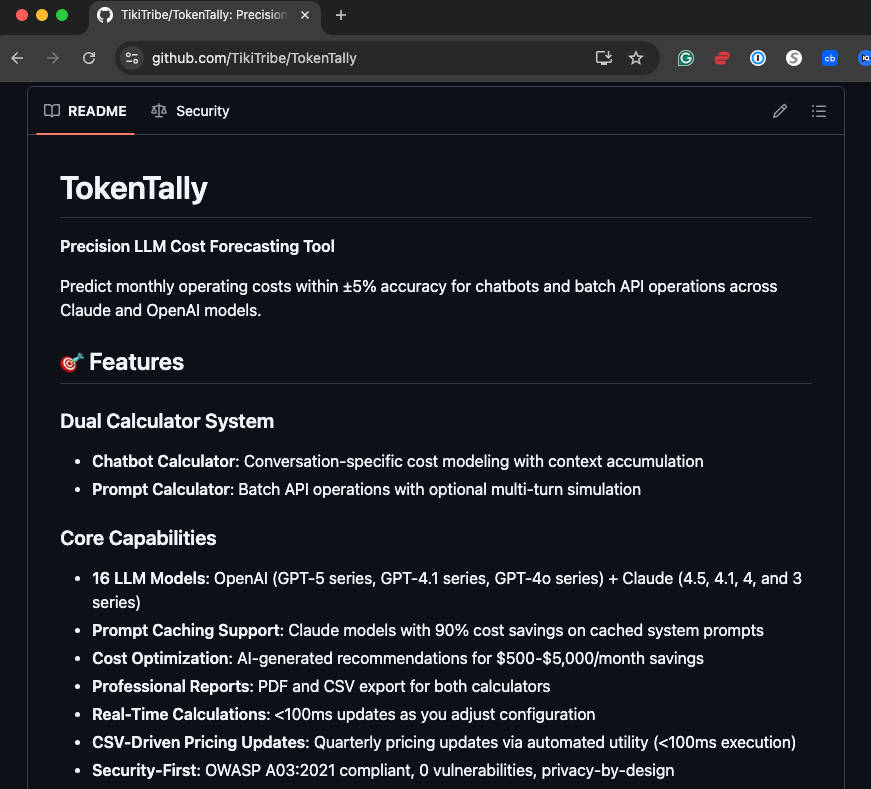
TokenTally is an open-source LLM cost calculator that models real-world usage. Not theoretical single prompts. Real multi-turn conversations with context accumulation and prompt caching. You can try it at https://tokentally-tt.vercel.app/ right now and download the code at https://github.com/TikiTribe/TokenTally.
It’s not another token counter. It’s a dual calculator system. The chatbot calculator models customer service bots, support agents, and interactive assistants. You tell it your average conversation length, message sizes, and monthly volume. It calculates first-turn costs separately from later turns. It simulates cache hits. It shows you what you’ll actually spend.
The prompt calculator handles batch operations. Content generation, document processing, anything where you’re running the same prompt thousands of times. It includes multi-turn mode for those workflows, too.
I built it to support 16 different LLM models across OpenAI and Anthropic. GPT-4o, GPT-4o Mini, all the Claude variants. Pricing updates ad hoc via CSV import. When OpenAI drops their prices again next month, you update one file. There is a script in the repo you can run to do it for you, so you can even schedule it to execute on a recurring basis.
What Makes TokenTally Different
Generic token calculators assume everything is a single API call. Input goes in, output comes out, multiply by price per token. Done.
Real chatbots don’t work that way. Turn one has no conversation history. Turn five has four previous exchanges in context. TokenTally models both.
The first turn calculation is straightforward. System prompt plus user message times input price. Response times output price. Standard stuff.
Later turns get complicated. The system prompt is cached for Claude models, reducing costs by 90%. User messages include accumulated context from the conversation. A 5-turn chat with a moderate context strategy adds 150 tokens per turn. That’s 600 extra tokens by turn five. Your cost just doubled, and most calculators missed it entirely.
Context accumulation follows three strategies: minimal (50 tokens per turn), moderate (150 tokens per turn), and full (300 tokens per turn). Customer support bots typically run minimal. Complex sales assistants? Full context. You pick what matches your use case.
Prompt caching simulation is where TokenTally really separates itself. Claude’s caching saves 90% on system prompts after the first turn. For a 500-token system prompt at $3 per million input tokens, you pay $0.0015 on turn one. Turns two through ten? $0.00015 each. At 10,000 conversations per month, that’s $135 in savings. TokenTally calculates this automatically. Other tools don’t even ask if you’re using caching.
The dual calculator approach means you’re not forcing chatbot logic into batch operations or vice versa. Each mode has its own algorithm tuned for that workflow. Chatbot mode emphasizes conversation turns and caching. Prompt mode emphasizes batch volume and output size presets.
The optimization engine analyzes your configuration and suggests improvements. Set your monthly conversation target too high with an expensive model? It’ll tell you. Not using caching when you should be? It flags it. Running full context strategy when minimal would work? It quantifies the savings. These aren’t vague suggestions. They’re prioritized recommendations with dollar amounts attached.
Think about how you’re currently making these decisions. You’re probably comparing pricing pages in different browser tabs. Building spreadsheets with formulas that assume single API calls. Guessing at usage patterns based on beta test data that doesn’t reflect production traffic. TokenTally consolidates all of that into a single interface, with algorithms that account for the nuances that matter.
Real Scenarios That’ll Make Your CFO Nervous
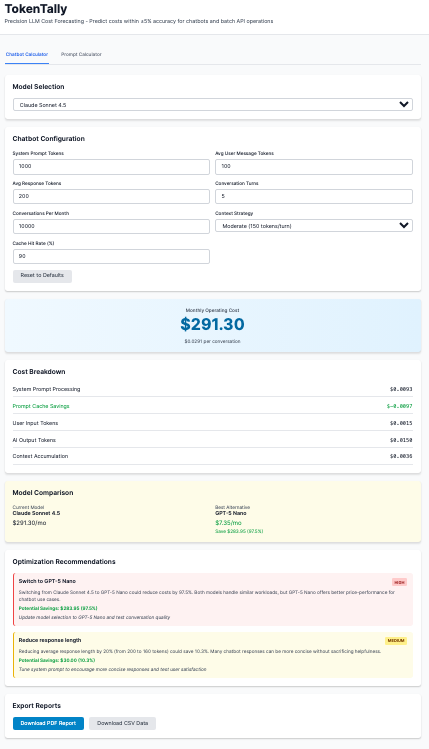
Let’s run my friend’s startup scenario. They want a customer service chatbot on their website.
Expected volume: 5,000 conversations per month.
Average conversation: 5 turns.
System prompt: 300 tokens.
User messages: 200 tokens.
Responses: 300 tokens.
Moderate context strategy.
Using Claude Sonnet 4 with 1% caching: $173.46 per month. Using Claude Sonnet 4 with caching: $159.05 per month. Using GPT-4o Mini: $7.27 per month. The most cost-effective option? GPT-5 Nano: $3.93/mo.
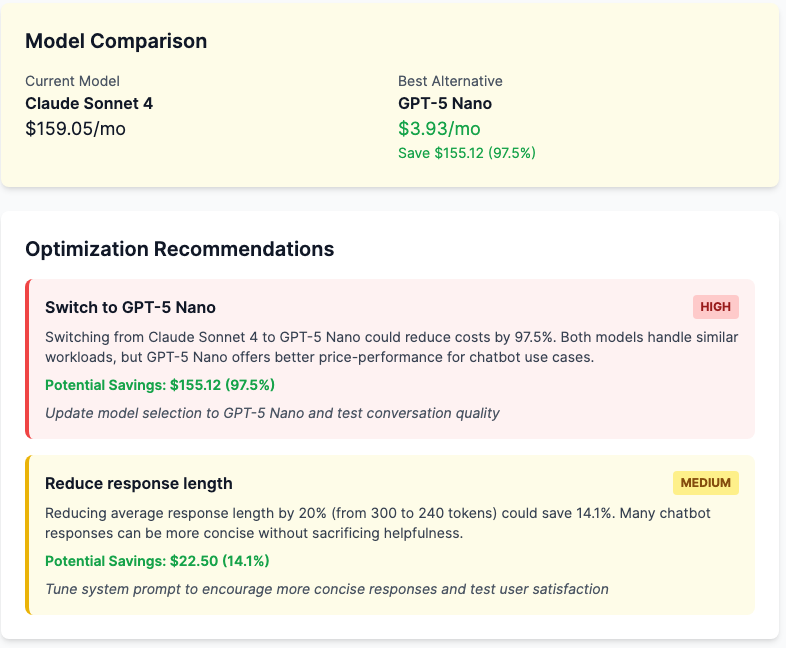
That’s a 97.5% savings between premium and budget models. For 5,000 conversations. Scale that to 50,000 conversations and you’re looking at $1590.45 for Claude Sonnet 4 with caching vs $39.25 for GPT 5 Nano. $15,51.20 monthly savings. That’s $18,614.40 annually.
Now, imagine you don’t know about context accumulation. You budget based on a single-turn estimate. You think each conversation costs $0.015. You’re actually paying $0.025. Your budget is off by 67%. Three months in, your finance team is asking why AI costs are double the forecast. You don’t have an answer because you didn’t model the right thing.
Or imagine you’re using Claude, but you don’t enable prompt caching. You’re paying $88.88 when you could be paying $74.88. That’s $14 per month per 5,000 conversations. It doesn’t sound like much until you’re at 500,000 conversations monthly. Now it’s $1,400 per month. $16,800 annually. For flipping one configuration flag.
Let’s try another scenario. You’re building an AI writing assistant. Users create long-form content through multiple iterations. 10-turn conversations are common. Full context strategy because users reference earlier parts of their content. 20,000 conversations per month. System prompt: 500 tokens. User messages: 150 tokens. Responses: 400 tokens.
Claude Sonnet 4 with caching: $462 per month. Claude Sonnet 4 without caching: $568 per month. GPT-4o: $494 per month (no caching available).
The savings from caching here are $106 per month. At this volume, that’s $1,272 annually. But here’s the thing: GPT-4o sits right in the middle price-wise, and it doesn’t offer caching. If you chose GPT-4o because you didn’t understand Claude’s caching advantage, you’re paying 7% more than you need to.
TokenTally shows you all of this upfront. Before you commit to a model. Before you set your pricing. Before your CFO schedules a meeting to ask why costs are out of control.
Try It, Break It, Improve It
TokenTally is open source at https://github.com/TikiTribe/TokenTally. You can run it locally or deploy it to Vercel in about three minutes. No backend, no database, no API keys required. Everything runs client-side.
The interface is straightforward. Pick your model. Enter your conversation parameters. Hit calculate. You get a cost breakdown showing first turn, cache write, later turns, and the monthly total. You get optimization recommendations prioritized by potential savings. You get a comparison view showing what you’d pay with alternative models.
Want to compare GPT-4o against Claude Sonnet 4 for your specific workload? Plug in your numbers once. Switch models. Instant comparison. No rebuilding spreadsheets. No hunting for pricing pages. Just answers.
The codebase is TypeScript with React and Tailwind CSS. The calculation engine is pure functions with zero dependencies. If you want to add a new model, you edit one CSV file and run an update script (provided in the repo). If you want to add a new optimization algorithm, you write one function. The architecture is clean, and the test coverage is comprehensive.
I built this tool because my friend needed it. Turns out I need it. You probably need it too. Whether you’re a startup founder trying to budget your first AI feature or an enterprise architect comparing vendor costs, TokenTally gives you real numbers.
Fork it. Extend it. Add models I haven’t covered. Build integrations with your cost tracking systems. Honestly, Gemini’s pricing page was difficult to scrape, and since I wanted to deploy this “same day,” I moved on.
Open issues for feature requests. Submit pull requests for improvements. This is a tool for the community, built by someone who got tired of doing token math on napkins.
My friend’s startup question? I sent them a link to TokenTally. Thier client can now make an informed decision. That’s the point.
Key Takeaway: You can’t manage AI costs if you can’t model them accurately, and TokenTally is the first calculator built for real-world multi-turn conversations with caching and context accumulation.
Call to Action
👉 Stop guessing what your LLM costs will be.
👉 Get TokenTally at https://github.com/TikiTribe/TokenTally and run your real numbers.
👉 Found a bug or want a feature? Open an issue. Built an improvement? Submit a PR. Need help? Check the docs, reach out directly on LinkedIn, or visit RockCyber for more AI security and governance resources.
👉 Subscribe for more AI security and governance insights with the occasional rant.