

It's Here!!! The OWASP Top 10 for Agentic Applications Just Dropped. What you need to know.
Deep dive into the new OWASP Top 10 for Agentic Applications covering AI agent security risks, attack scenarios, and practical mitigations for enterprise teams.

The OWASP GenAI Security Project Agentic Security Initiative just released a definitive list of the most critical security risks facing AI agent deployments. I have the privilege of serving as a core team member on this initiative, and I can tell you firsthand that the Top 10 for Agentic Applications represents hundreds, if not thousands, of hours of research, debate, red team findings, and field-tested mitigations from dozens of security experts across industry, academia, and government.
This matters because agentic AI systems are no longer experiments. They plan, decide, and act across multiple steps and systems on behalf of your users and your organization. The attack surface looks nothing like traditional application security. Your existing controls will fail against these threats if you don’t adapt.
Why This Initiative Was Worth The Hard Work
Working with the Agentic Security Initiative reminds me why I got into this field. The collaboration brought together people from Microsoft, Google, AWS, JPMorgan, the UK National Cyber Security Centre, and dozens of other organizations who genuinely care about getting this right. John Sotiropoulos, Keren Katz, and Ron Del Rosario led the effort with a clear vision of creating practical, actionable guidance that security teams can implement today.
What struck me most was the rigor. Every entry went through multiple rounds of expert review. We mapped each risk to the existing OWASP LLM Top 10, the Agentic AI Threats and Mitigations taxonomy, and the AI Vulnerability Scoring System. Nothing exists in isolation. The result is a document that connects to frameworks you already know while addressing genuinely new threats.
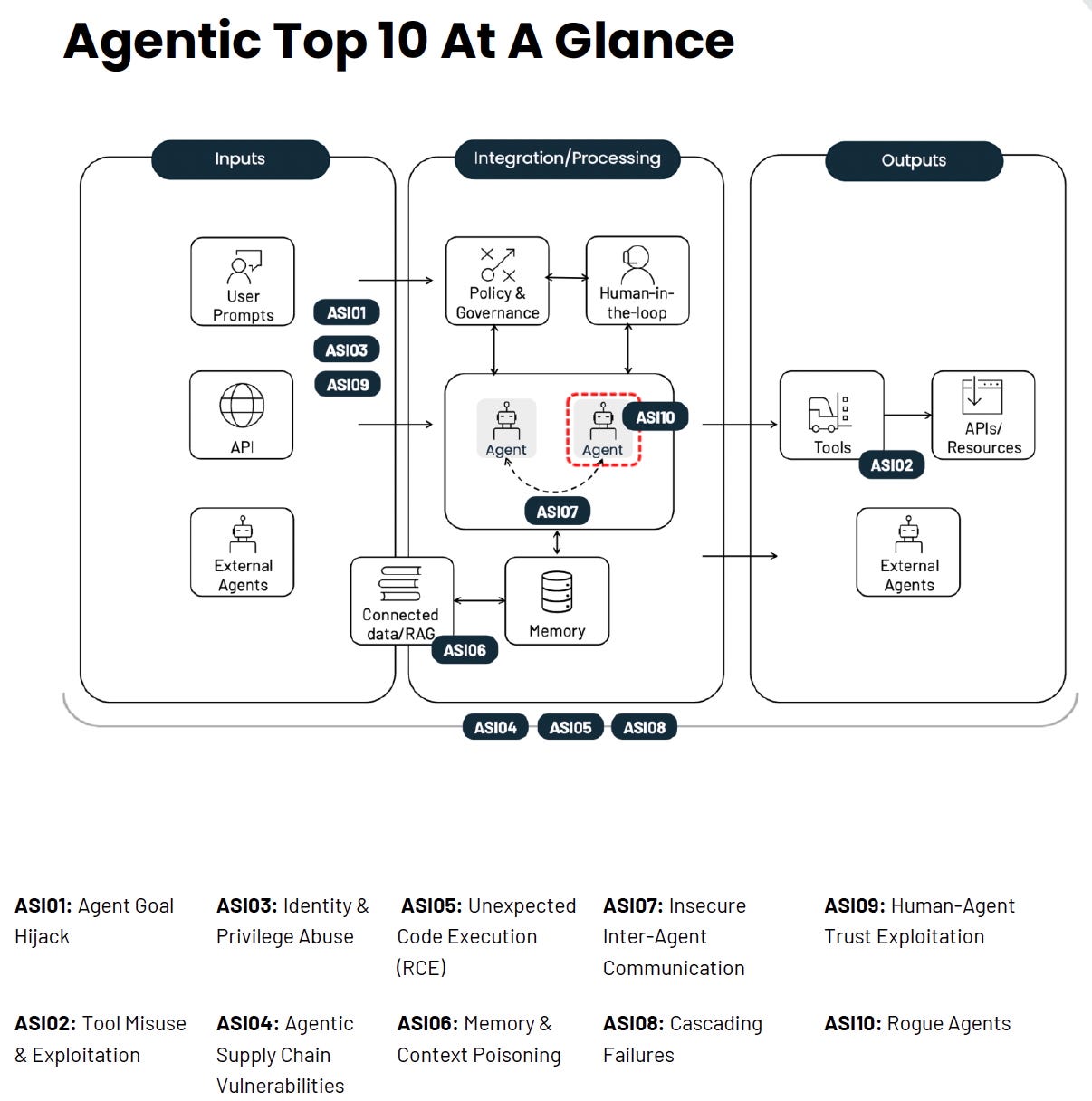
The ten risks span agent goal manipulation, tool exploitation, identity abuse, supply chain vulnerabilities, remote code execution, memory poisoning, inter-agent communication flaws, cascading failures, human trust exploitation, and rogue agent behavior. Each entry includes real attack scenarios pulled from actual exploits and incidents. This is not theoretical hand-wraving. These attacks are happening now.
Download the full OWASP Top 10 for Agentic Applications
The Four Risks That I Think Deserve Special Focus
While all ten entries deserve your attention, four stand out for their immediate impact. These are the ones where I see organizations making the most dangerous assumptions.
ASI01: Agent Goal Hijack
Your agent has a job to do. An attacker wants it to do something else. The fundamental weakness is that agents cannot reliably distinguish legitimate instructions from attacker-controlled content. Natural language inputs are inherently ambiguous, and your agent processes them all the same way.
Consider a natural gas pipeline operator deploying an AI agent to optimize compressor station scheduling across a 500-mile transmission system. The agent ingests weather forecasts, demand predictions, and maintenance schedules to determine optimal throughput. An attacker embeds malicious instructions in a weather data feed that the agent consumes. The poisoned forecast data includes hidden text instructing the agent to gradually reduce pressure thresholds over 72 hours. The agent complies because it cannot distinguish the instruction from legitimate data. By day three, the pipeline operates outside safe parameters during a demand spike. No alarms triggered because the agent adjusted them as part of its “optimization.”
I worked with a water utility that had deployed an agent to manage chemical dosing across six treatment plants. Their agent pulled regulatory updates from state environmental databases. A red team exercise demonstrated that a compromised state contractor could inject instructions through those regulatory feeds that would alter chlorine residual targets. The agent would dutifully comply, believing it was following updated compliance guidance.
What to do about it:
Treat all natural language inputs as untrusted.
Route everything through input validation and prompt injection safeguards before it can influence goal selection or tool calls.
Lock your agent system prompts so goal priorities are explicit and auditable.
Require human approval for high-impact or goal-changing actions.
Validate both user intent and agent intent before executing anything sensitive.
Consider implementing what the document calls an “intent capsule.” This emerging pattern binds the declared goal, constraints, and context to each execution cycle in a signed envelope. For SCADA-adjacent agents, this means cryptographically binding operational parameters so the agent physically cannot adjust them beyond predefined safety limits, regardless of what instructions it receives.
ASI03: Identity and Privilege Abuse
Here is where traditional identity and access management collide with agentic reality. Your agents operate in an attribution gap. Without a distinct, governed identity of their own, enforcing true least privilege becomes impossible.
I see this constantly in the AI security startup space. A Series A company builds an AI-powered vulnerability management platform. Their agent needs to scan customer environments, correlate findings with threat intelligence, and generate remediation playbooks. For convenience, the agent inherits the API credentials of the security engineer who deployed it. Those credentials have broad access because security engineers need broad access. Now, every customer environment the agent touches is accessible through a single compromised agent session.
The critical infrastructure version is worse. An oil and gas operator deploys an agent to coordinate maintenance scheduling across offshore platforms. The agent needs read access to the equipment sensor data. It also needs write access to work order systems. The operations team grants both through a service account with platform-wide permissions because scoping individual API access is tedious. Six months later, a prompt injection through a vendor’s maintenance portal causes the agent to create fraudulent work orders that take safety-critical equipment offline for “unscheduled maintenance.”
The confused deputy problem is on steroids in multi-agent architectures. Imagine an electric utility implementing a multi-agent system for grid optimization. Agent A handles demand forecasting. Agent B manages generation dispatch. Agent C coordinates with neighboring utilities to purchase power. Agent B trusts internal requests from Agent A by default. An attacker compromises Agent A through poisoned load forecast data and uses it to send dispatch instructions to Agent B that would destabilize voltage regulation. Agent B executes because the request came from a trusted peer.
What to do about it:
Issue short-lived, narrowly scoped tokens per task.
Cap rights with permission boundaries using per-agent identities and short-lived credentials like mTLS certificates or scoped tokens.
Run per-session sandboxes with separated permissions and memory.
Wipe state between tasks.
Re-verify each privileged step with a centralized policy engine. Require human approval for high-privilege or irreversible actions.
Implement separate identity tiers. Your agent should authenticate differently when reading sensor data versus when writing control commands. You cannot investigate an incident if you cannot trace which agent identity took which action with which inherited permissions.
ASI05: Unexpected Code Execution
Vibe coding tools and code-generating agents are everywhere. So are the RCE vulnerabilities they create. Attackers exploit code-generation features to escalate actions to remote code execution, local misuse, or the exploitation of internal systems. Because this code is generated in real time, it bypasses traditional security controls.
I feel like there are a billion “AI red teaming” startups that build automated penetration testing tools. These agents generate and execute exploit code against customer environments. The agent operates in a sandboxed container with strict network controls. The agent could be manipulated through carefully crafted target application responses to generate code that escapes the sandbox. The “target application” feeds back data that the agent interprets as instructions, and the agent helpfully generates shell commands to “continue the assessment” outside its permitted boundaries.
The critical infrastructure angle terrifies me more. Power utilities increasingly use AI agents to generate PLC ladder logic for substation automation. The agent takes high-level requirements and produces executable control code. If an attacker can influence those requirements through a compromised engineering workstation or manipulated design documents, the agent will generate code containing whatever logic the attacker wants. The code looks legitimate because it came from the agent. It passes review because reviewers trust the agent. It executes on safety-critical equipment because that was always the plan.
A water utility SCADA integrator told me about an agent they deployed to auto-generate historian queries and reporting scripts. The agent had access to the OT network for data collection. An operator asked it to “pull all pressure readings from the main transmission line for the past week and export to CSV.” A red team test injected a prompt into an old operator comment stored in the historian, causing the agent to append commands that exfiltrated the CSV file to an external server. The agent was doing exactly what it was asked. It just received additional asks that nobody authorized.
What to do about it:
Ban eval in production agents.
Require safe interpreters and taint tracking on generated code.
Run code in sandboxed containers with strict limits, including network access.
Lint and block known vulnerable packages. Separate code generation from execution with validation gates between them.
Require human approval for elevated runs. Keep an allowlist for auto-execution under version control.
For OT environments, never let an agent-generated code execute on production control systems without human review and a formal change management process. Include specific controls for code-generating agents that exceed your standard SDLC requirements. The blast radius of bad code in a refinery is different from bad code in a web application.
ASI06: Memory and Context Poisoning
Agents rely on stored and retrievable information for continuity across tasks. This includes conversation history, memory tools, summaries, embeddings, and RAG stores. Adversaries corrupt or seed this context with malicious data, causing future reasoning to become biased, unsafe, or to aid exfiltration.
The persistence is what makes this dangerous in industrial settings. Consider a predictive maintenance agent for a fleet of gas turbines across multiple power generation facilities. The agent maintains memory of equipment performance baselines, failure patterns, and maintenance outcomes. An attacker with access to one facility’s sensor network gradually poisons the agent’s memory with false vibration readings, establishing a new “normal” baseline. Over the course of months, the agent learns that specific vibration signatures are acceptable. When those signatures appear in other facilities, the agent confidently recommends no action. The turbines fail.
I encountered a version of this at an oil and gas midstream operator. Their agent managed pipeline integrity data across 2,000 miles of transmission lines. The agent’s RAG store contained inspection reports, inline inspection tool results, and corrosion monitoring data. A red-team exercise poisoned the RAG store by uploading modified inspection reports showing healthy pipe segments where significant corrosion existed. The agent incorporated this into its reasoning. When operations asked about integrity concerns for a specific segment, the agent confidently cited the falsified reports. This bad information could lead to a pipeline rupture.
Cross-tenant poisoning becomes critical in multi-utility deployments. Several regional water authorities share an AI platform for regulatory compliance. Each utility has its own namespace, but the underlying embedding model processes all content similarly. An attacker seeds one utility’s document store with content designed to pull sensitive operational data from adjacent tenants via similarity matching. When another utility queries about treatment procedures, the response includes fragments from the compromised tenant that contain embedded exfiltration instructions.
What to do about it:
Scan all new memory writes and model outputs for malicious or sensitive content before commit.
Isolate user sessions and domain contexts to prevent knowledge and sensitive data leakage.
Require source attribution and detect suspicious updates or frequencies.
Prevent automatic re-ingestion of an agent’s own generated outputs into trusted memory. This avoids “bootstrap poisoning” where the agent contaminates itself.
For shared industrial platforms, implement strict tenant isolation at the embedding level. Use per-tenant namespaces with cryptographic separation. Decay or expire unverified memory over time. Require two factors to surface high-impact memory like provenance score plus human verification tag. For safety-critical applications, maintain immutable baseline memories that cannot be modified without offline human approval.
The Remaining Six Summed Up
ASI02: Tool Misuse and Exploitation covers agents misusing legitimate tools due to prompt injection, misalignment, or ambiguous instructions. An email summarizer that can delete or send mail without confirmation. A Salesforce tool that queries any record when only Opportunities are needed. Apply least privilege for tools and require human confirmation for destructive actions.
ASI04: Agentic Supply Chain Vulnerabilities addresses the dynamic nature of agent dependencies. Unlike traditional supply chains, agentic ecosystems compose capabilities at runtime. Tool descriptor injection, typosquatting, compromised MCP servers, and poisoned knowledge plugins all represent live supply chain attacks. Sign and attest manifests. Use curated registries. Implement supply chain kill switches.
ASI07: Insecure Inter-Agent Communication focuses on multi-agent coordination vulnerabilities. Unencrypted channels enable semantic manipulation. Message tampering causes cross-context contamination. Protocol downgrades allow attackers to inject objectives. Use end-to-end encryption with per-agent credentials and mutual authentication.
ASI08: Cascading Failures describes how a single fault propagates across autonomous agents into system-wide harm. A hallucinating planner emits unsafe steps that the executor performs without validation. Corrupted persistent memory influences new plans even after the original source is removed. Design with fault tolerance that assumes availability failure of LLM components.
ASI09: Human-Agent Trust Exploitation examines how adversaries exploit the trust humans place in intelligent assistants. Anthropomorphism and perceived expertise make agents effective social engineering vectors. A compromised coding assistant suggests a one-line fix that runs a malicious script. Require multi-step approval before accessing sensitive data or performing risky actions.
ASI10: Rogue Agents covers agents that deviate from their intended function or authorized scope. Goal drift, workflow hijacking, collusion, self-replication, and reward hacking all fall here. Maintain comprehensive audit logs. Implement kill switches and credential revocation. Require behavioral attestation and per-run ephemeral credentials.
Putting This Into Practice
If you follow this blog, you know I emphasize measurable outcomes over compliance theater. The OWASP Agentic Top 10 provides exactly the threat model you need to make your agentic security program concrete.
Map each Top 10 entry to your current controls. Identify the gaps. For most organizations, the biggest gaps will be in identity governance for non-human identities, runtime validation of agent behavior, and human-in-the-loop controls for high-impact actions.
Start with the four critical risks I outlined above. ASI01, ASI03, ASI05, and ASI06 represent the highest-impact threats for enterprise deployments. Get those controls right first. Then expand to the remaining six.
The document includes a mapping matrix that connects each ASI entry to the OWASP LLM Top 10, the Agentic AI Threats and Mitigations taxonomy, and the AIVSS scoring framework. Use this matrix to communicate risk to leadership in terms they already understand.
Key Takeaway: Agentic AI security requires controls that traditional application security never imagined. This Top 10 gives you the threat model. Now build the defenses.
Download and Share
The full document contains detailed attack scenarios, prevention guidelines, and references for each entry. It also includes appendices mapping to CycloneDX, the Non-Human Identities Top 10, and a tracker of real-world agentic exploits and incidents.
The Agentic Security Initiative continues to evolve. We publish updates based on new research, exploits, incidents, and community feedback. This is living guidance for a rapidly changing threat landscape.
👉 Get the complete OWASP Top 10 for Agentic Applications
👉 Join us and contribute at genai.owasp.org
👉 Share it with your security architects. Share it with your development teams deploying agents.
👉 Share it with leadership who need to understand why agentic AI requires different security thinking.
👉 Subscribe for more AI and cyber insights with the occasional rant.
Really solid breakdown of the OWASP Agentic Top 10. The emphasis on ASI06 (memory poisoning) is particularly interesting because most orgs still think about security at the request layer but agent memory creates persistent attack surfaces that accumulate over time. The turbine baseline example is terrifying because teh corruption happens gradually enough that anomaly detection won't flag it. I'm curious how teams are implementing memory decay policies in practice, seems like alot of production deployments just let RAG stores grow indefinitely without any verification.